注:本文虽以 Docker 进行演示,但 Docker 并不是必须的,相关软件也可以直接安装到计算机上
背景
如果我们是Web应用的开发者,会对响应时间、接口的稳定性等比较敏感,在站点尚未部署到生产环境时,我们有充足的时间来进行调试、分析哪些接口需要优化。但当应用发布后,想要继续跟踪,可能需要通过日志记录请求和响应时间、记录响应状态码等,然后通过其它工具进行分析外,或是与其它一些分析工具进行集成。
另外现在十分流行的大屏:比如最近曝光的12306监控中心,大屏上显示出的当日售出车票数量、移动端和Web端订票比例、线路热度等信息;还有每年双十一,各大电商的大屏显示出交易总金额、热卖榜等等。
可以发现,上面列出的各点皆为指标:响应时间、成功率等我们可以理解为技术指标,当日售出车票数量、交易总金额等则是业务指标。当我们定义好指标后,需要有收集这些指标的方式,我们采用监控的方式来采集数据。当然,若是某些值超出了阈值,还需要及时发出警报,但这不在本文的讨论范围内了。最后再将监控到的内容进行展示(可视化),就需要用到本文的两个主角 —— Prometheus 和 Grafana。
Prometheus
Prometheus is an open-source systems monitoring and alerting toolkit -- Prometheus Overview
Prometheus 是一款开源的监控和警报工具包 —— 译自 Prometheus Overview
为什么选择 Prometheus
Prometheus 的几大特点:
- 多维数据模型,时间序列数据由指标名称和键/值对标识
- 提供能在多维度上灵活查询的 PromQL 语言
- 不依赖分布式存储,单服务器节点自治(single server nodes are autonomous)
- 基于 HTTP PULL(拉取)的方式采集时序数据
- 可通过中间网关推送时序数据
- 可通过服务发现或静态配置要采集的目标服务器
- 支持多种图表和仪表盘
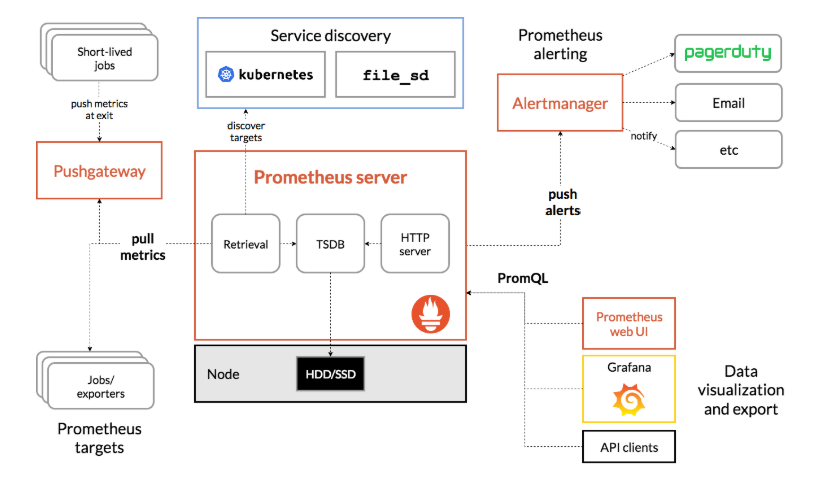
相比 InfluxDB 等时序数据库,Prometheus 内置了时序、监控和通知等功能。
安装 Exporter 和 Prometheus
首先安装 Exporter,Exporter 将监控的各种指标以 HTTP 的方式暴露出来。这里通过 Docker 来安装和运行
docker run -d -p 9100:9100 prom/node-exporter
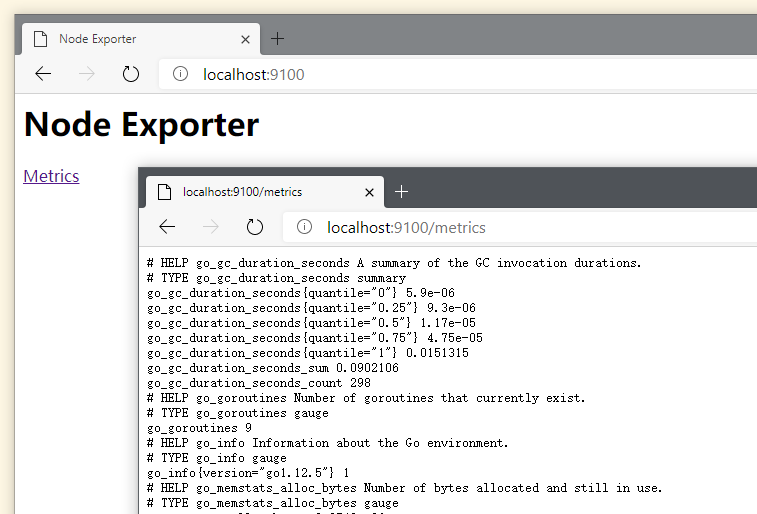
然后就能通过 http://localhost:9100 来访问它,点击下方的 Metrics 链接,页面上就会将相关指标以文本的形式展示出来。
安装 Prometheus 前需要先将配置文件准备好,新建一个 prometheus.yml 文件
global:
scrape_interval: 15s
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
labels:
instance: prometheus
- job_name: node_exporter
static_configs:
- targets: ['10.0.0.150:9100']
labels:
instance: node_exporter
scrape_interval 为抓取间隔时间,下面配置了两个 job,并以 static_configs 的方式配置了两个目标: localhost:9090 (后面要安装的 Prometheus,意思是监控自己)和 10.0.0.150:9100(监控 node_exporter。注意,这里的 10.0.0.150 是计算机的内网 IP,请根据实际情况修改)
接下来安装 Prometheus,因为 prometheus.yml 配置文件需要提映射到 Docker 容器中,记得把硬盘设置为共享
docker run -d -p 9090:9090 -v "D:\docker\prometheus\prometheus.yml:/etc/prometheus/prometheus.yml" --name prometheus prom/prometheus
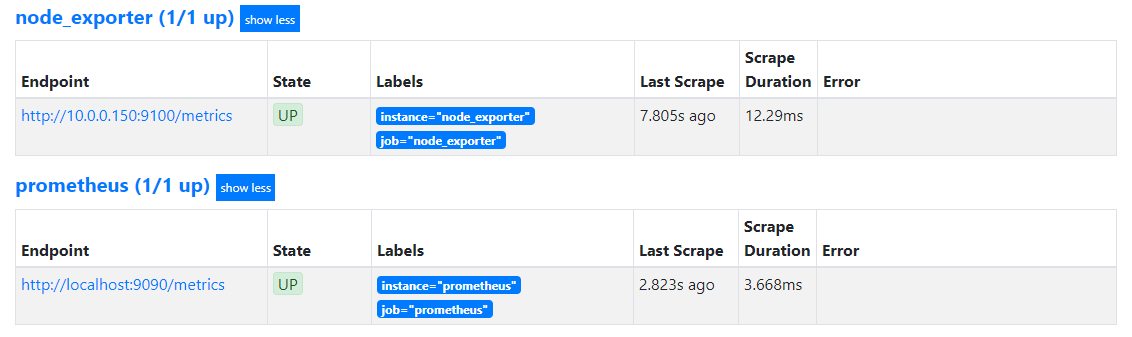
通过浏览器访问 http://localhost:9090 就能访问 Prometheus 了,我们先看一下监控的目标是否已经上线,访问 http://localhost:9090/targets 应该能看到 node_exporter 和 prometheus 两个目标。State 是 Up 表示已经上线,如果是 Unknown 可以稍等一会儿再刷新。Labels 部分显示了配置文件中配置的 job 以及 instance,后面查询的时候会用到。
当到了抓取的时间,Prometheus 就会去访问目标的 /metrics 页面将相关指标采集并储存。
指标类型
Prometheus 提供了四种指标类型
Counter计数器,只增不减,重启后清零。可用于记录请求数量、已完成任务的数量、错误数量等。Gauge仪表盘,可增可减。可用于记录当前温度、当前内存占用值等。Histogram直方图Summary摘要
关于直方图和摘要,都用于统计和分析样本的分布情况,这里引用 prometheus-book 中关于它们的介绍:
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如CPU的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统API调用的平均响应时间为例:如果大多数API请求都维持在100ms的响应时间范围内,而个别请求的响应时间需要5s,那么就会导致某些WEB页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在010ms之间的请求数有多少而1020ms之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram和Summary都是为了能够解决这样问题的存在,通过Histogram和Summary类型的监控指标,我们可以快速了解监控样本的分布情况。
—— prometheus-book 使用Histogram和Summary分析数据分布情况
之前我们访问过 http://localhost:9100/metrics 指标页面,节选如下:
## HELP promhttp_metric_handler_requests_total Total number of scrapes by HTTP status code.
## TYPE promhttp_metric_handler_requests_total counter
promhttp_metric_handler_requests_total{code="200"} 162
promhttp_metric_handler_requests_total{code="500"} 0
promhttp_metric_handler_requests_total{code="503"} 0
## TYPE 一行末尾体现了指标类型,非 # 开头的行内容为:指标名称、标签(花括号内的部分)和样本值。Prometheus 以时间序列的方式储存数据,即每个样本是按照时间顺序储存的,在 Prometheus 储存的这些样本内容中包含了:指标,时间戳及样本值。
PromQL
PromQL 是 Prometheus 的查询语言,我们访问 http://localhost:9090 时能看到查询页面。在 Expression 中输入
promhttp_metric_handler_requests_total
并按下回车,可以看到这样的结果,这段 PromQL 将该指标的指标和样本值进行了返回
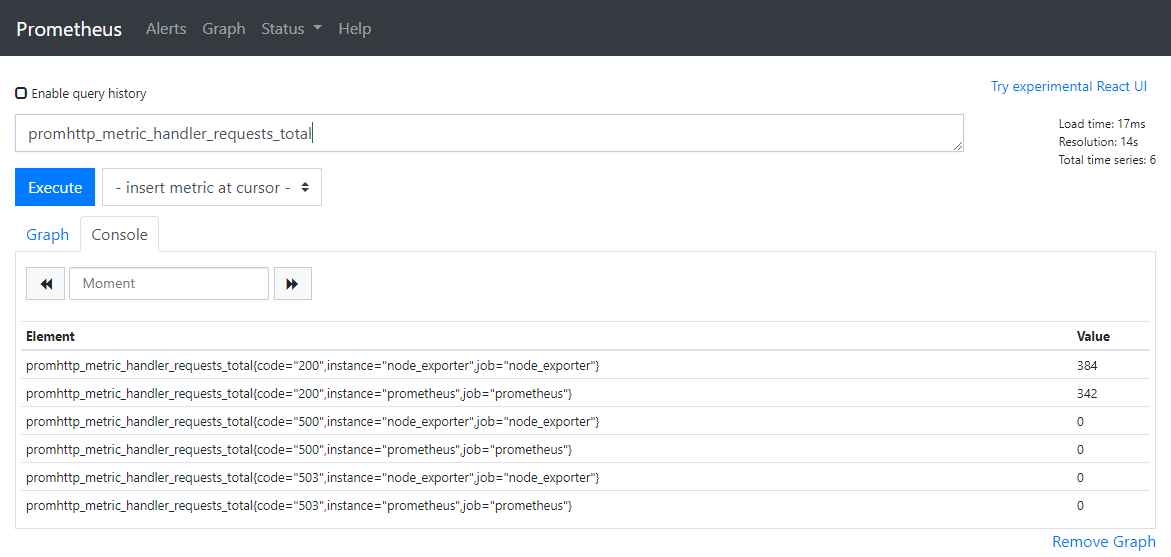
因为 node_exporter 和 prometheus 都提供了名为 promhttp_metric_handler_requests_total 的指标,若想只看 node_exporter 的该指标,则在 PromQL 中加上花括号来过滤 Labels 即可:
promhttp_metric_handler_requests_total{instance="node_exporter"}
当然,PromQL 的内容远不止这些,待日后再记录。
Grafana
Grafana 是一款数据可视化工具,先来直观的感受一下吧,也可以访问 Grafana Live Demo 体验。
好了,先来安装 Grafana,这里映射了一个本地文件夹到容器中
docker run -d -p 3000:3000 -v "D:\docker\grafana:/var/lib/grafana" --name grafana grafana/grafana
然后通过 http://localhost:3000 访问 Grafana,默认用户名密码均为 admin。
首先进入 Home 页面,选择 Add data source 添加我们的 Prometheus 作为 Grafana 的数据源。需要注意的是,如果和我一样使用 Docker,那么 Prometheus 的 URL 不能写 localhost,需要填写计算机的内网 IP 。
我们已经通过 Prometheus 采集了一批数据样本,现在只需要添加一个新报表来呈现。在左侧栏中依次选择 Create - Dashboard,然后选择 Add Query(如果显示的是 Panel,把鼠标移动到 Panel Title 上,会出现菜单,选择 Edit 来编辑它)。
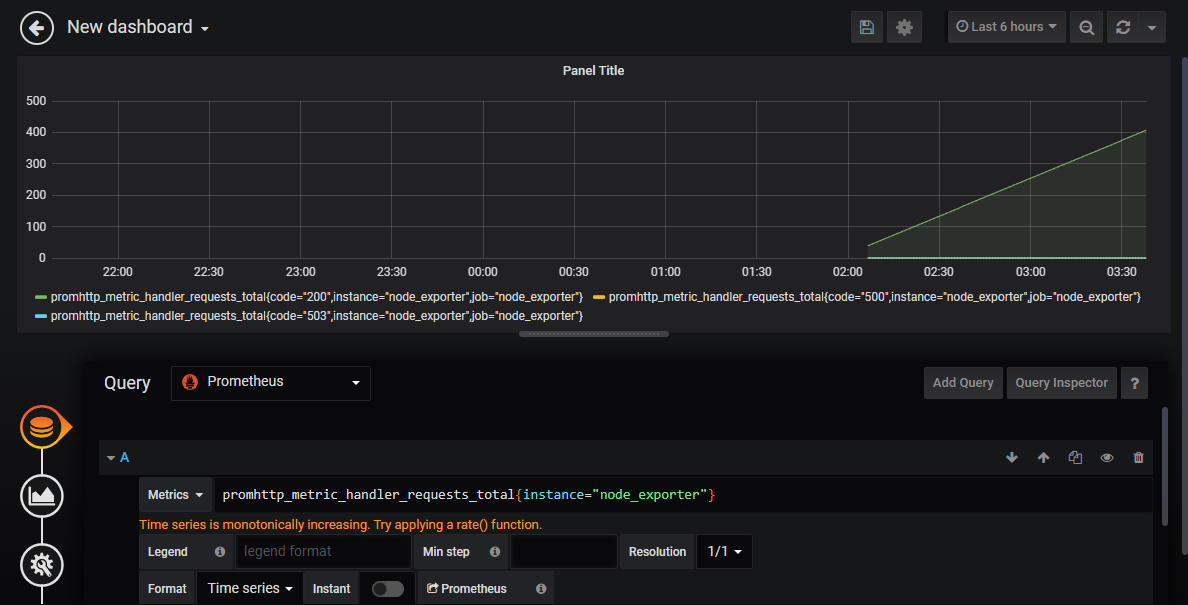
将数据源(Query)修改为刚刚添加的 Prometheus 后,Metrics 中输入和刚刚在 Prometheus 里一样的 PromQL 语句 promhttp_metric_handler_requests_total{instance="node_exporter"} 然后按下回车,可视化的数据就生成了。
本文到此就结束了,简单的介绍了 Prometheus 和 Grafana。后面还会介绍往 ASP.NET 中添加指标,并让 Prometheus 来抓取,以及 PromQL 等的详细内容。